Paper: Modeling Movement: A machine-learning approach to track migration routes after displacement
This paper introduces a model for extracting levels of local violence by identifying violent terminology in news articles. The idea being that violence in a region is one of the driving factors for causing forced displacement. They use time-sensitive topic modeling.
Key Pieces
Extracting violence scores from media articles
This is a topic modeling method. Documents are analysed to extract the relationship between words and topics by comparing their frequency across many documents. Non-negative matrix factorisation (NMF) is used to build topics in an unsupervised way. The method is as follows:
Matrix $V$ with documents as columns and words as rows where the elements are the frequency of the word in the document. This can be factorised into:
\[V=WH\]with, for the jth document and kth topic:
\[V(:,j) \approx \sum^r_{k=1}W(:,k) H(k,j)\]Each document (column in $V$) can be considered formed from a set of topics, $r$. $W$ is a features matrix assigning words to hidden topics, $k$. $H$ is a weights matrix that maps the topics to documents. The number of topics, $len(r)$, is a key pre-defined quantity that affects the quality of the identified topics - too many topics means that the topics are too niche, too few and the topics are too broad and vague. $len(r)$ is optimised by scanning different values and using semantic analysis to evaluate the topics that are constructed.
Predictive Model
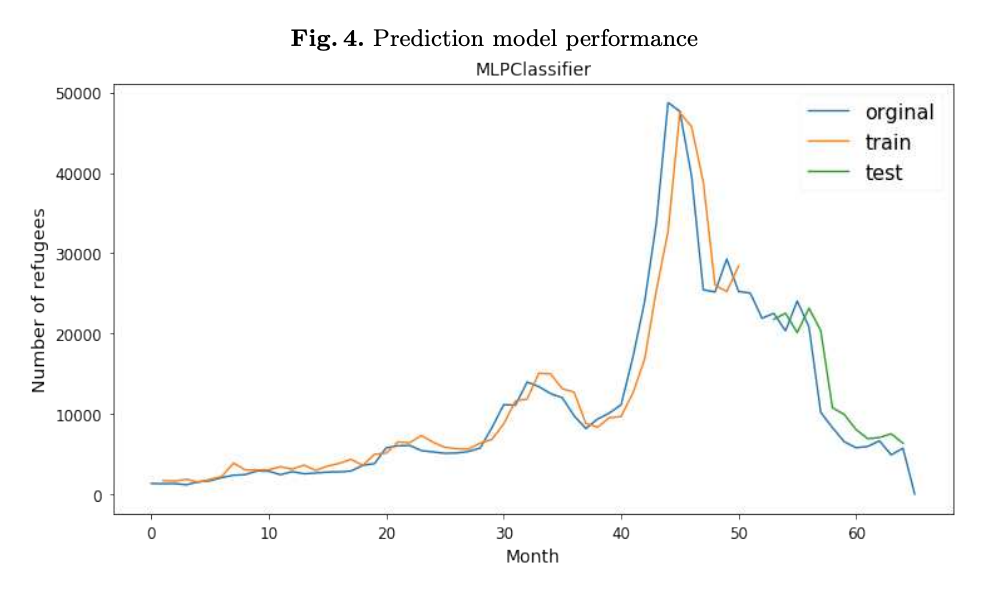
Topic analysis is done in month chunks. The violent topics are identified by hand, violence measure is the number of violent topics divided by the total number of topics for a document. This is combined with lag variables (previous numbers of refugees) for each month as input for a predictive regression model. A walk forward evaluation of the model is performed: a prediction is given for a given month, the RMSE is calculated for this prediction, at the next month the true value for this month is provided as input. Three models are build that predict t+1, t+2 and t+3 months ahead. The most successful model for based on the RMSE value is a Multi-Layer Perceptron regression model. The best model for classifying the topics identified into one of seven pre-defined areas:
- violence/terrorism
- economic issues
- environmental issues
- political issues
- religious
- conflicts
- refugee crisis
- relief
The best classifier model, based on measures of precision, recall and F1 score is Stochastic Gradient Descent. The paper mentions that the classifier model impacts the performance of the prediction model but doesn’t mention this much (maybe it is complicated and extensive). The classifier performance is very impressive based on historical data.
Aside: LDA (Latent Dirichlet Allocation) (TDS article).
This is a method for grouping words into a (pre-defined) number of (not defined) topics. The documents are represented as groups of topics.
The method is to:
- Randomly assign words in the dataset to a topic
- Calculate the proportion of words in a document that are assigned to a given topic \(P(word\|topic)\)
- Calculate the proportion of documents containing a word that are assigned to a topic \(P(topic\|document)\)
- Calculate the probability that a word is associated with a given topic \(P(word\|topic)\) = \(P(topic\|document) \times P(word\|topic)\)